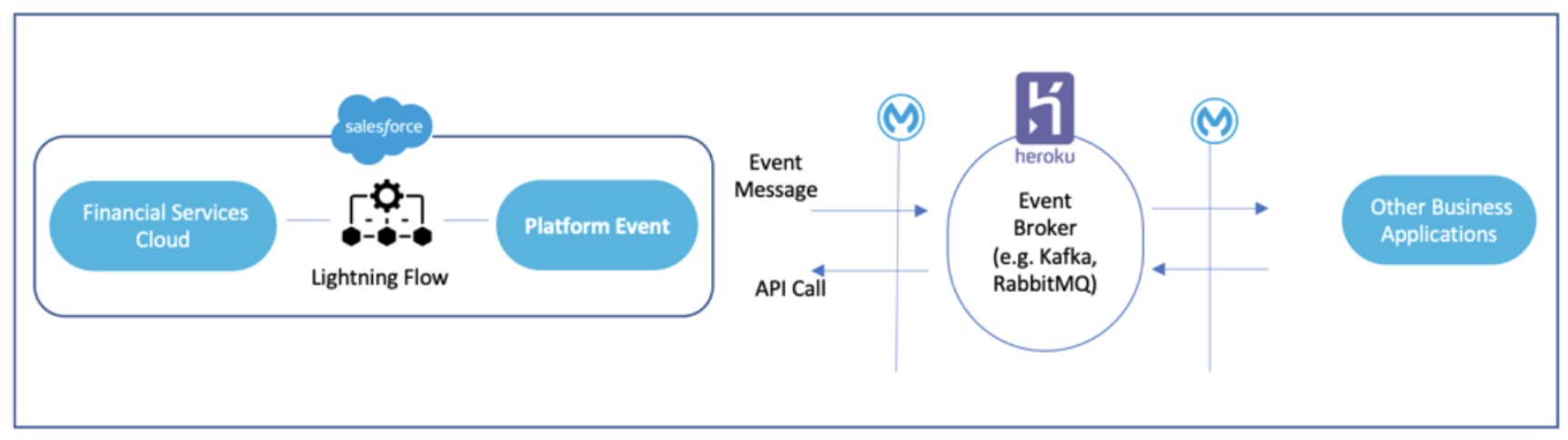
A couple of years back I built a step-by-step event-driven-architecture workshop (https://trailhead.salesforce.com/trailblazer-community/feed/0D54S00000Bd0PQSAZ) spanning Kafka, RabbitMQ, Salesforce, MuleSoft, and Heroku.
By building an end-to-end application that connected Kafka, RabbitMQ, Salesforce Platform Events, MuleSoft, and Heroku, I moved beyond theory and learned how APIs, eventing, and webhooks really behave in practice. This experience helped me understand how to choose the right design for a microservices-based architecture and gave me hands-on lessons in troubleshooting complex integrations — from checking if data actually landed in RabbitMQ, to figuring out whether an issue was with Kafka emitting an event or the consumer catching it.
Integration is far more than plugging in a connector between two systems; it’s about understanding state, flow, and failure points across distributed components so the whole system remains reliable.
However before we select an integration pattern and start building, it is good to understand some foundational concepts. Let’s first consider, how do the three communication Patterns – REST, Eventing, and Webhooks – fit into an integration architecture?

REST: Stateless Requests and Discrete Round Trips
REST is the familiar request–response model.
Statelessness: Every request is independent; the server does not remember past requests. Each call carries authentication (OAuth token, API key) and parameters needed to complete it.
Discrete round trips: REST is designed around “ask and respond.” Even with keep-alive connections, the logical unit is still one request followed by one response.
Simple mental model: If a client wants data, it asks for it.
Consideration: REST works best for on-demand interactions, where the client explicitly triggers each request. When continuous updates are needed, this usually means the client must poll the server, which can create extra network traffic and introduce slight delays before changes are noticed.
Eventing: Long-Lived Streams and Decoupled Systems
Eventing flips the model. Instead of asking for updates, clients subscribe to streams of events.
How connections work in Apache Kafka: Understanding long-lived TCP sockets and gRPC.
-
Traditionally in eventing, Consumers open long-lived TCP sockets to the message bus. They send a Fetch request, which the broker may hold until data arrives (long polling). Consumers track offsets to resume from any point.
Kafka natively implements its own binary protocol over long-lived TCP sockets. Consumers connect to brokers with persistent sockets, issue Fetch requests that the broker can hold until new records arrive, and rely on offsets to resume from any point in the log. This custom protocol, designed before HTTP/2 and gRPC existed, handles batching, compression, replication, and flow of events directly at the Kafka layer — streaming is baked into Kafka itself, not layered on top.
-
The relatively new gRPC by contrast, is a general RPC framework built on HTTP/2 that many modern eventing systems use to expose streaming pub/sub APIs.
gRPC streaming standard for eventing has a similar outcome as traditional long-polling, but cleaner: a single persistent HTTP/2 stream carries events and acknowledgments both ways. No need to renew fetch requests repeatedly.With server- or bidi-streaming RPCs, a single persistent stream carries events and acknowledgments both ways without renewing fetch requests. It offers a standardized transport with features like multiplexing and built-in flow control.
In other words, Kafka solved streaming with its own native protocol, while gRPC provides a standardized way for newer systems to achieve the same continuous event delivery pattern.
There is also growing interest in combining the two: building gRPC-based APIs that sit on top of Kafka. These gRPC layers act as facades, translating a Kafka topic into a streaming RPC so clients can consume events without implementing the Kafka protocol directly. The advantage is developer ergonomics and interoperability — gRPC clients exist in every major language, and streaming APIs feel natural in microservice environments. The considerations are performance and feature depth. Some implementations continue to use Kafka’s native protocol for high-throughput workloads plus it exposes the full semantics of offsets, partitions, and batching. gRPC layers simplify access but add translation overhead and may not expose all of Kafka’s tuning knobs.
What do we mean by this buzz-word – “continuous emission?” When we say producers “just emit events,” we mean: The producer writes to a topic/log without caring about who is listening.
It does not address a specific consumer.
It does not wait for the consumer to be available.
If a record is created, the producer appends an event. That’s it.
Contrast this with REST: if a record is created and you want someone else to know, you must target them with a POST request. That’s direct, synchronous, and consumer-aware.
Decoupling is another buzz word we hear in connection with event driven architectures. Let’s unpack decoupling – there are multiple dimensions in which eventing facilitates decoupling.
Event-driven systems decouple producers from consumers on three axes:
Time: Consumers can connect later; brokers persist events.
Space: Producers don’t need to know who or how many consumers exist.
Synchronization: Producers don’t block waiting for consumers to act.
This makes eventing scalable, fault-tolerant, and flexible. You can add new consumers tomorrow, replay yesterday’s events, or keep processing while another service is down.
Webhooks: Lightweight Push from APIs
Webhooks bridge REST and eventing. They let SaaS platforms push updates to you via HTTP.
How webhooks work
Subscribe: Your app registers at a provider’s subscription endpoint (e.g., POST /subscriptions).
Subscription object created: The provider stores your webhook URL and knows to call you when something happens.
Delivery: When the event occurs, the provider POSTs a JSON payload to your webhook endpoint.
Characteristics of webhooks
Lightweight: Any web server can receive webhook calls.
Direct push: No polling needed.
Examples: GitHub pushes commit events, Stripe pushes payment notifications, Microsoft Graph pushes mailbox updates.
Webhooks compared to eventing
Scalability: Each subscriber adds direct load — the provider must POST to all of them.
Persistence: If your server is down, you may miss events (though retries help).
No replay: Unlike Kafka, you can’t go back and re-read events later.
So webhooks are excellent for SaaS-style integrations but may don’t replace a full event based architecture.
Webhooks Vs Eventing: Why event buses scale differently than webhooks
I have explained above that in webhooks each subscriber adds direct load — the provider must POST to all of them. However even in the case of eventing, consumers send a Fetch request, which the broker may hold until data arrives (long polling) – so even in event bus the broker has to do some work per consumer. So why is eventing considered more scalable than webhooks?
Both webhooks and event buses do per-consumer work, but the nature and cost of that work are very different.
Webhooks: The producer (e.g., Stripe, GitHub, MS Graph) must make a separate outbound HTTP request to every subscriber. If 10,000 consumers are registered, that’s 10,000 HTTP POSTs per event. Each POST carries connection overhead, retries, TLS handshakes, etc. The scalability cost grows linearly with the number of subscribers, and the producer owns all that load.
Event bus (Kafka, RabbitMQ, etc.): The broker holds events in a log/queue, and consumers fetch or stream them. Yes, the broker does per-consumer work (tracking offsets, managing connections, serving data), but it doesn’t initiate N outbound requests per event. Instead, the cost is amortized: one copy of the event is written to durable storage, and multiple consumers can independently read from that same storage. The per-consumer cost is predictable and lower than webhook-style fan-out.
So in summary webhooks work based on a push model where the producer does the heavy lifting for every consumer. Event bus works based on a pull/stream model where the consumer does the work to fetch, and the broker just serves from a shared log.
FAQ: Clearing Up Common Questions
(1) “Message Bus just emits events” — what exactly does that mean?
In REST, a producer has to know the consumer and target it directly.
In eventing message bus, the producer appends to a topic and walks away. It has no knowledge of who, when, or how events are consumed. That decoupling — fire-and-forget into a shared log — is what makes eventing fundamentally different.
(2) What does “stateless REST” really mean?
REST servers do not keep session context between requests.
If you need state, you keep it in a database, cache, or persistence layer, not in the API tier itself.
This is why REST systems scale horizontally: servers are disposable and interchangeable.
What happened to EJBs? Stateful Enterprise JavaBeans tried to hold conversational state in server objects, but this made scaling hard (state tied to a single JVM). The industry shifted toward stateless APIs + external persistence, which is more elastic.
(3) Where do OData, OpenAPI, Graph API, GraphQL, Composite APIs and SOAP APIs fit?
OData APIs are REST-based services that follow a formal standard (OASIS/ISO) for exposing data with consistent conventions for querying, filtering, and metadata. They extend plain REST by defining a uniform query syntax ($filter, $select etc.) and a machine-readable schema that enables easy discoverability.
At the same time, this means that we optimal design of OData APIs is important. servers must guard against overly expensive queries – for example, deep $expand queries may cause the server to run many small database calls instead of efficient joins, leading to performance issues. In addition, OData queries can get long and complex because filters, selects, and nested expansions are all encoded in the URL.
What makes OData different from REST is that OData is a formalized standard on top of REST. While plain REST leaves it up to each API to invent its own query parameters, pagination rules, and schemas, OData defines them all: filtering, projections, joins/expansions, ordering, batching, and a machine-readable $metadata document describing the entire entity model. That metadata-driven approach means OData is not just transport — it encodes the data model and query language in a consistent, discoverable way.
Example 1: list of products over $100, sorted by creation date
Plain REST: GET /products?minPrice=100&sort=createdAt_desc&limit=25 – Each API development team invents his/its own query parameters such as minPrice, sort, limit.The same request in OData looks like: GET /Products?$filter=Price gt 100&$orderby=CreatedAt desc&$top=25 – Here, $filter, $orderby, and $top are part of the OData standard, so every OData API supports them consistently.
Example 2: Fetching nested data
In REST: multiple calls for related entities
GET /orders/123
GET /orders/123/customer
GET /orders/123/itemsOData: one call with $expand to pull related data inline
GET /Orders(123)?$expand=Customer,ItemsBecause of this metadata-first design, virtualization patterns are easier with OData. A client (say, Salesforce Connect) can connect to any OData endpoint, automatically read the $metadata, and issue live queries without requiring the data to be copied or pre-staged. The endpoint behaves like a virtual database: clients can filter, sort, join, and paginate remotely, and the OData provider translates those operations into underlying queries (SQL, ERP lookups, etc.). With plain REST, you’d need custom endpoints for every shape of query, and virtualization tools wouldn’t know how to introspect or optimize them.
Fetching related data in one call instead of many – this is a problem that is solved in different ways by OData, Composite APIs and GraphQL.
OData $expand: Standardized query option built into the OData spec. The server understands how to inline related entities because relationships are defined in the $metadata model. It’s still REST under the hood (one HTTP GET), but with query semantics prescribed by the OData standard.
Composite APIs: Usually custom endpoints defined by the API developer (e.g., /orderWithCustomerAndItems/123). They hardcode the aggregation logic on the server side. Less flexible, but predictable.
GraphQL: Client-driven. The query explicitly declares the exact fields and nested relationships (e.g., order { id customer { name } items { productName } }). The server resolves whatever shape the client asks for.
So OData sits between composite APIs and GraphQL: more flexible than fixed composites (because $expand can target any defined relationship), but GraphQL may be more flexible (which allows arbitrary nesting and field selection).
Despite the flexibility of GraphQL, OData remains great because it delivers standardized querying, rich metadata for discoverability, and seamless integration with enterprise tools (e.g., Excel, Power BI, SAP, Dynamics) — all without the need for a custom gateway or resolver layer.
What is OpenAPI? – OpenAPI is not an API style but a specification for describing APIs, most commonly REST. An OpenAPI document (YAML/JSON) defines endpoints, parameters, schemas, and authentication in a machine- and human-readable way, enabling automated documentation, client SDK generation, validation, and governance. In this sense, OpenAPI plays the same role for REST that WSDL played for SOAP: a formal contract. Unlike OData or GraphQL, it does not dictate query semantics or runtime behavior — it standardizes the description layer, making APIs more consumable, consistent, and governable across teams and platforms.
What is Swagger in context of OpenAPI? The OpenAPI specification was originally known as Swagger (created by Reverb in 2010, later acquired by SmartBear), and in 2016 it was donated to the Linux Foundation under the new name OpenAPI Specification (OAS). Swagger still exists today as a tooling ecosystem (Swagger UI, Swagger Codegen) built around OpenAPI, but OpenAPI itself is the vendor-neutral standard.
OData vs OpenAPI: Both OData and OpenAPI expose machine-readable schemas – so what makes them different?
Both OData and OpenAPI expose machine-readable schemas, but they serve different purposes: OData’s $metadata is a runtime feature built into the protocol, tightly coupled to its query language so clients can discover entities and immediately issue $filter, $select, or $expand queries without custom logic.OpenAPI’s YAML/JSON spec is a design-time contract (originally known as Swagger) that describes endpoints, parameters, and models for documentation, validation, and code generation. Unlike OData, it is usually published separately from the API and does not itself define or drive query semantics.
SOAP APIs: Older XML-based standard. Still request–response, still consumer-aware. Can carry heavier session and security contracts, but not fundamentally different from REST in coupling.
Graph APIs is basically a design pattern for REST APIs in such a way that instead of exposing only flat resources (/users, /messages), the API arranges endpoints to reflect relationships between entities (/users/{id}/messages, /groups/{id}/members). This makes the REST API feel navigable like a graph of nodes and edges, but it’s still built on standard REST conventions.
So essentially, Graph APIs (e.g., Microsoft Graph) are collections of REST endpoints organized in a “graph-like model.” A “graph-like model” means the API organizes entities as nodes (e.g., users, groups, messages) and exposes their relationships as edges via REST paths (e.g., /users/{id}/messages, /groups/{id}/members), letting clients traverse data through linked resources much like navigating a graph — though it’s still REST under the hood, not GraphQL.
GraphAPIs may add features like webhooks or delta queries for change notifications, but they remain REST under the hood (no broker, no replay, not true event buses). Despite the similar name, GraphQL is entirely different: it’s a technology standard (created at Facebook, now under the GraphQL Foundation) that lets clients query exactly the fields they need — even from multiple related entities — in a single request against a typed schema. This makes API calls more efficient by reducing both over-fetching (getting too much data) and under-fetching (needing multiple calls). Unlike composite APIs (which bundle several REST calls into one server-defined response), GraphQL is client-driven: the consumer specifies the exact data shape, making it more flexible and eliminating the need for versioned composite endpoints.
Summary: REST, Eventing, Webhooks
REST: Stateless, request–response, good for on-demand queries.
Eventing: Long-lived, decoupled, scalable streams, good for real-time systems.
Webhooks: Lightweight push, great for SaaS integrations, but limited scalability and persistence.
Each reflects a different philosophy:
REST asks for data.
Eventing streams data.
Webhooks deliver data.
Choosing wisely means understanding not just the API surface, but the connection model, state management, and scaling implications.
References: End-to-End EDA Hands-on Workshop
I created the following eventing architecture workshops to help you learn event driven architecture (for both Kafka and RabbitMQ) from a practical standpoint. These workshops include complete step-by-step instructions on how to deploy an eventing architecture.
The workshop is available for download (together with webinar recording) from https://trailhead.salesforce.com/trailblazer-community/feed/0D54S00000Bd0PQSAZ and from platformdemos.com. I have also included direct links to the workbooks in references below.
The one caveat is that the workshops were build using Mule Cloud Flow Designer – the Cloud Flow Designer is no longer available. You would need to use Mule AnyPoint Studio today (or Mule Anypoint Code Builder). I know of people who have been able to successfully use this workshop with Mule Anypoint Studio so it’s certainly possible though you would to need do some instrumentation on your own.
Even if you can’t run the workshop as-is, reading through the workshop guides will give you a very good picture of an end-to-end event driven architecture can be constructed.
Step-by-step Event Driven Architecture: RabbitMQ with Salesforce Platform Events, MuleSoft, Heroku: https://github.com/lightningexperience/finscabin/blob/main/PDF-WORKBOOKS/EDA-RabbitMQ-Salesforce%20Event-Driven%20Architecture%20Hands-on%20Workshop_%20Student%20Workbook.pdf
Step-by-step Event Driven Architecture: Kafka with Salesforce Platform Events, MuleSoft, Heroku: https://github.com/lightningexperience/finscabin/blob/main/PDF-WORKBOOKS/EDA-Kafka-Salesforce%20Event-Driven%20Architecture%20Hands-on%20Workshop_%20Student%20Workbook.pdf
Screenshots of EDA Workshop (RabbitMQ) Steps: https://github.com/lightningexperience/finscabin/blob/main/PDF-WORKBOOKS/EDA-RabbitMQ-Workbook%20Supplement_%20Screenshots.pdf
Troubleshooting Event Driven Architecture: https://github.com/lightningexperience/finscabin/blob/main/PDF-WORKBOOKS/EDA-Troubleshooting-Salesforce%20Event-Driven%20Architecture%20Hands-on%20Workshop_%20Student%20Workbook.pdf
890 total views, 2 today